Copilot Studio & Azure AI - Creare chatbot evoluti RAG-driven
-
Denis Dal Molin
- 29 May, 2025
- 08 Mins read

Introduzione
L’intelligenza artificiale applicata al mondo enterprise sta attraversando una fase di grande trasformazione, grazie all’integrazione di tecnologie sempre più avanzate.
In questo scenario si inserisce l’approccio RAG (Retrieval Augmented Generation), una metodologia che permette di andare oltre la semplice ricerca integrando la capacità di recuperare informazioni e generare risposte contestuali e accurate.
Copilot Studio funge da hub integrato per l’orchestrazione degli agenti e la gestione dei flussi di dialogo. In modo analogo, Azure AI Foundry si configura come una piattaforma centralizzata pensata per lo sviluppo, la sperimentazione e la gestione di soluzioni di intelligenza artificiale all’interno dell’ecosistema Azure, consentendo di integrare modelli, dati e servizi in modo semplice e scalabile.
I servizi Azure AI sono molto versatili e coprono tutte le principali aree: dalla ricerca intelligente sui dati, all’elaborazione del linguaggio naturale con Large Language Models, dalla visione artificiale, al riconoscimento e gestione di documenti, fino a strumenti per la personalizzazione e l’apprendimento automatico.
Cosa sono gli agenti?
Gli agenti sono assistenti AI conversazionali programmati per eseguire attività specifiche o rispondere a domande, interagendo anche con sistemi esterni tramite API, connettori o plugin.
Grazie a Copilot Studio, questi agenti possono essere arricchiti con logiche personalizzate, flow conversazionali dinamici e connessioni con fonti dati o knowledge base.
- Rispondono alle domande recuperando o riepilogando le informazioni
- Eseguono azioni quando richiesto, automatizzano i flussi di lavoro e sostituiscono le attività ripetitive
- Operano in modo indipendente, pianificano, apprendono e inoltrano in modo dinamico
Gli agenti coordinano una raccolta di modelli linguistici, insieme a istruzioni, contesto, fonti di conoscenza, argomenti, azioni, input e trigger per raggiungere gli obiettivi desiderati.
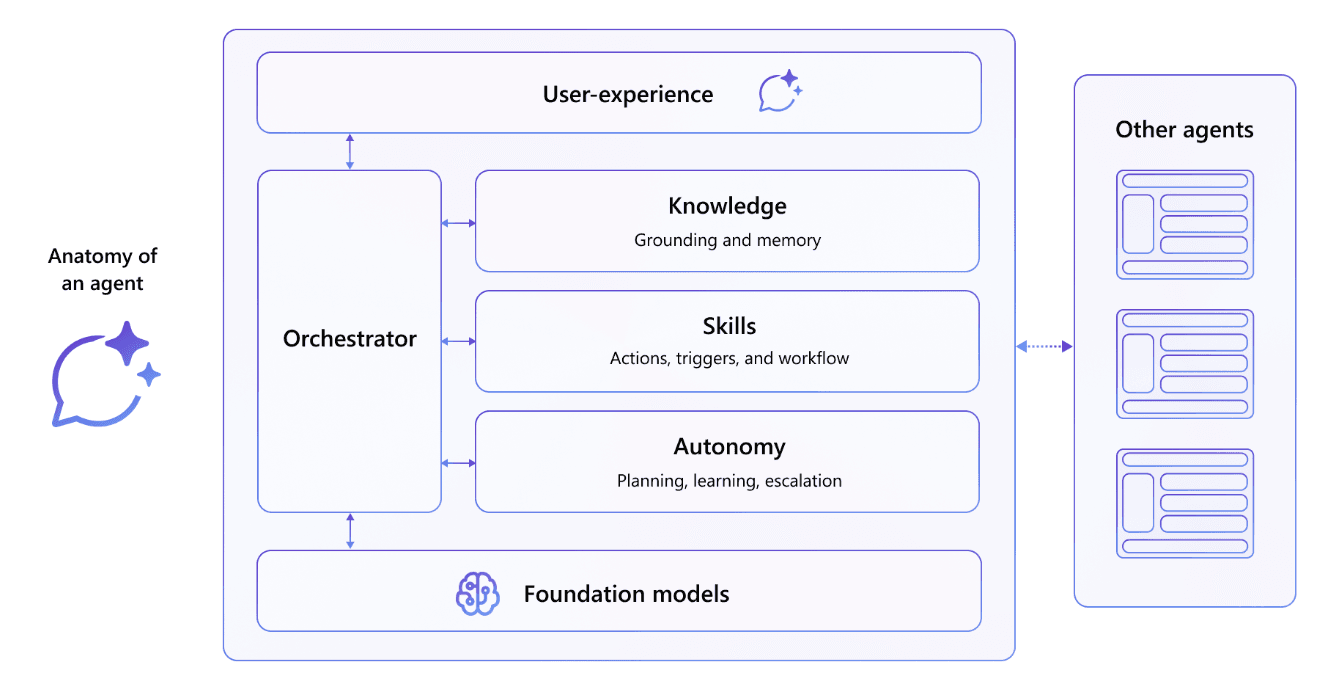
In Copilot Studio, gli agenti sono costruiti attorno a due concetti chiave:
- Argomenti
- Azioni
Argomenti
Gli argomenti sono i mattoni fondamentali delle conversazioni in Copilot Studio.
Ciascun argomento rappresenta un insieme coerente di domande, risposte e logiche di interazione relative a uno scenario specifico o a una particolare esigenza dell’utente.
- Attivazione tramite frasi trigger:
Ogni argomento viene avviato da una o più “frasi trigger”, ovvero domande o affermazioni che l’utente può digitare per avviare lo scenario (ad esempio: “Come faccio a prenotare una sala?”) - Sequenza strutturata di interazioni:
Una volta attivato, l’argomento segue un percorso definito composto da messaggi, domande all’utente, condizioni logiche e passaggi tra diversi nodi, questo schema permette di guidare l’utente passo a passo e adattare la conversazione in base alle sue risposte. - Capacità dinamiche:
Gli argomenti possono richiamare azioni (come lanciare un workflow o interagire con servizi esterni), porre domande per raccogliere informazioni, generare risposte personalizzate oppure spostare la conversazione su sottotemi correlati, mantenendo comunque coerenza rispetto allo scenario iniziale
In pratica, un argomento crea una sorta di micro-conversazione focalizzata, ad esempio per gestire richieste di ferie, aprire un ticket di supporto o rispondere a FAQ sulle policy aziendali.
Azioni
Le azioni rappresentano i “mattoncini operativi” all’interno di Copilot Studio: sono le unità fondamentali attraverso cui l’agente esegue compiti pratici e automatizza i processi.
Ogni azione corrisponde a un passaggio concreto, come inviare un messaggio, porre una domanda all’utente, effettuare una chiamata a un servizio esterno, salvare una variabile o avviare un workflow automatizzato.
Copilot Studio Vs Azure AI Foundry
Azure AI Foundry e Copilot Studio rappresentano due approcci distinti e complementari nell’ecosistema Microsoft per lo sviluppo di soluzioni basate su intelligenza artificiale, ciascuno con aree di applicazione, target utente e livelli di personalizzazione ben precisi.
Azure AI Foundry è pensato per sviluppatori, data scientist e team IT che necessitano di massima flessibilità e controllo sulla modellazione, training e distribuzione di soluzioni AI avanzate:
- Sviluppare, addestrare e validare modelli di machine learning personalizzati partendo da zero o utilizzando framework open-source
- Gestire pipeline di dati, orchestrare esperimenti, monitorare e valutare le performance dei modelli
- Integrare direttamente modelli nel cloud (es. con servizi Azure OpenAI, Cognitive Services, AutoML) e su larga scala
- Supportare un ciclo di vita completo della soluzione AI, dalla raccolta dei dati fino al deployment sui sistemi aziendali
Copilot Studio, invece, nasce come piattaforma low-code/no-code pensata per utenti business, consulenti IT e citizen developer:
- Permettere la creazione rapida di agenti conversazionali, chatbot e automazioni tramite un’interfaccia visuale intuitiva
- Integrare gli agenti con fonti dati aziendali (es. SharePoint, Dataverse, repository interni) e con servizi cloud Microsoft o di terze parti
- Sfruttare il framework Copilot (LLM, prompt engineering, knowledge grounding) per estendere o personalizzare le capacità di Copilot for Microsoft 365 in scenari aziendali specifici
- Consentire la pubblicazione degli agenti su diversi canali (Teams, siti web, app aziendali) senza dover scrivere codice complesso
È possibile, in certi casi, collegare modelli creati in Azure AI Foundry come plugin o servizi richiamabili da Copilot Studio, per ottenere soluzioni personalizzate e avanzate, mantenendo facilità d’uso per l’utente finale.
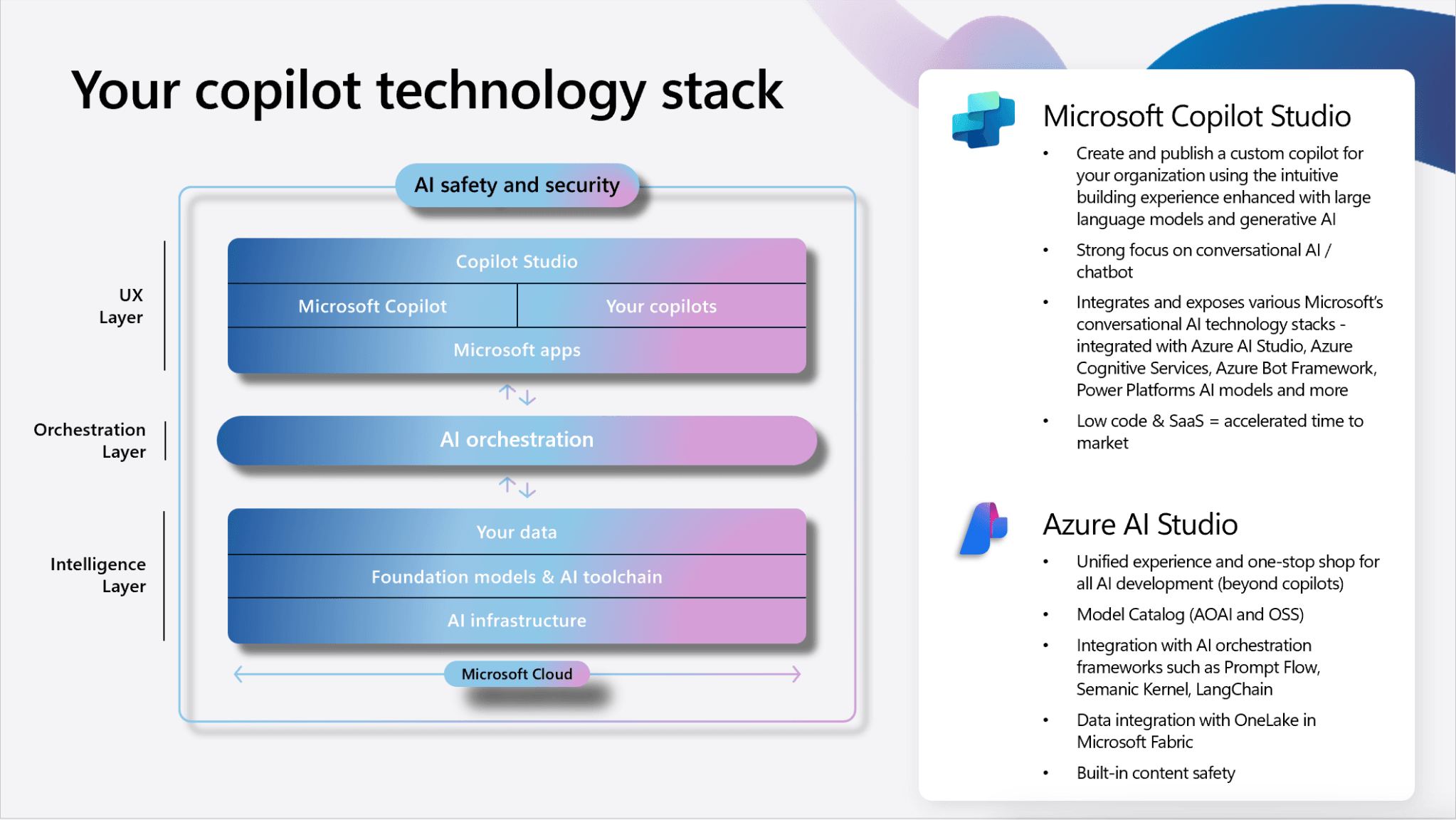
Azure AI Foundry - Hub & Project
Quando si lavora con progetti complessi di intelligenza artificiale su Azure AI Foundry, è importante conoscere bene le differenze tra le varie unità organizzative offerte dalla piattaforma.
Due concetti chiave sono quelli di hub e progetto: queste strutture aiutano a organizzare e gestire in modo efficiente sia le risorse condivise che le iniziative più specifiche.

In Azure AI Foundry l'hub e il progetto svolgono ruoli complementari ma distinti nell’organizzazione e gestione delle risorse AI.
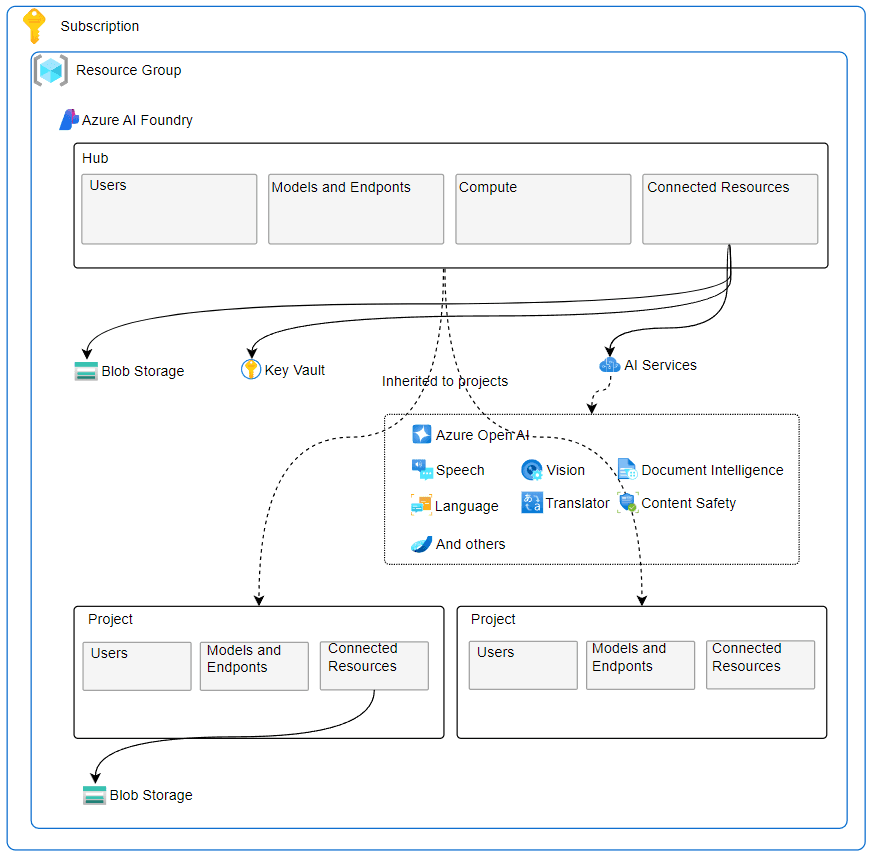
L’hub rappresenta l’ambiente centrale che raggruppa e collega tutti gli asset, le risorse e i servizi necessari per vari progetti di intelligenza artificiale: funge da punto di coordinamento a livello organizzativo e consente di gestire in modo centralizzato connessioni, sicurezza (inclusi ruoli e permessi), modelli, dataset e risorse computazionali condivise tra più team o progetti.
Il progetto, invece, è un contenitore specifico e isolato all’interno di un hub, dedicato a uno use case, soluzione o workflow AI ben preciso. Ogni progetto eredita le risorse e le impostazioni di sicurezza dell’hub, ma consente a team diversi di lavorare in parallelo su modelli, pipeline, deployment e inferenze riferite al loro ambito, mantenendo separazione logica e tracciabilità delle attività.
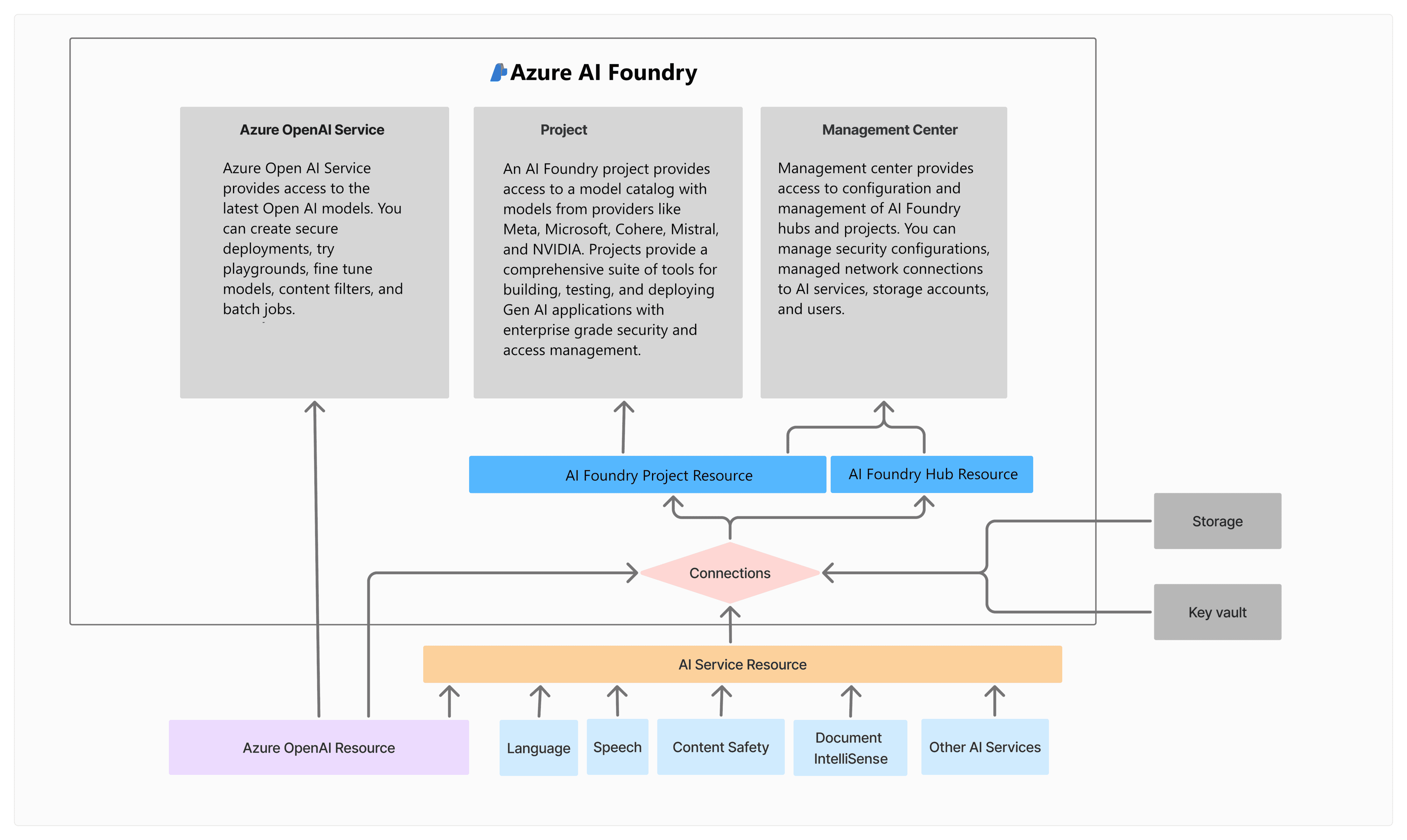
Passaggi chiave del flusso
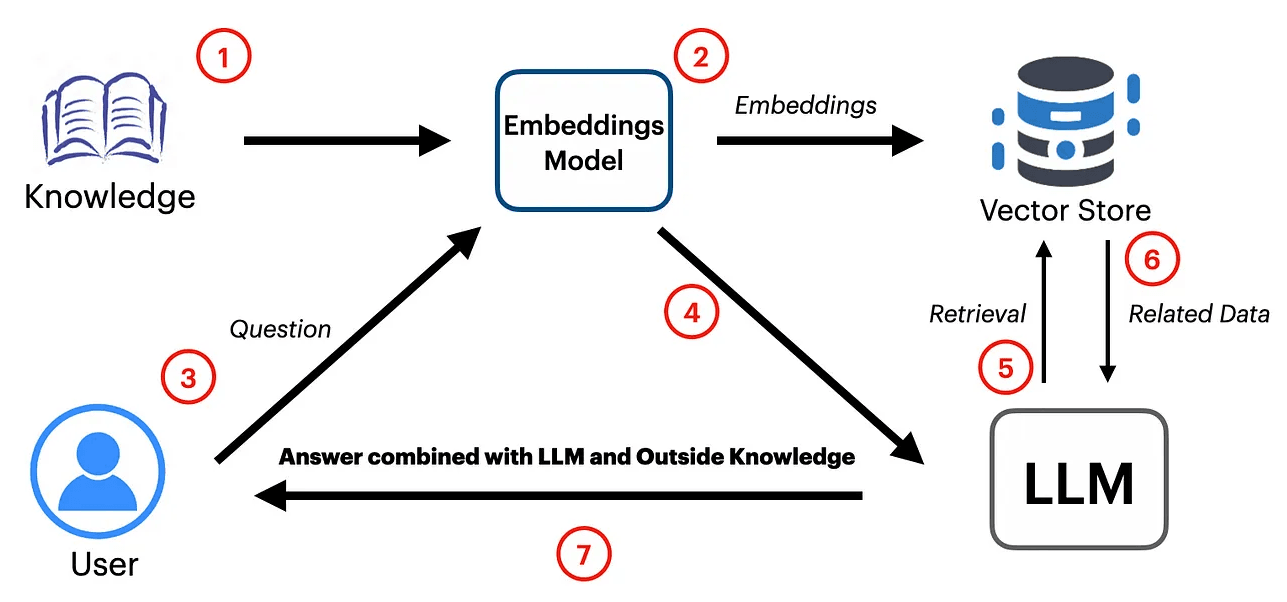
Un’integrazione RAG in ambito chatbot prevede questi passaggi essenziali:
- L’utente invia una domanda al chatbot
- Il sistema cerca informazioni rilevanti
- I documenti più pertinenti vengono utilizzati per arricchire il contesto della domanda
- Un modello generativo costruisce la risposta usando sia la richiesta dell’utente che i documenti recuperati
- Il chatbot restituisce all’utente una risposta più precisa, aggiornata e personalizzata
(Proof of Concept): Chatbot avanzato RAG-driven
Un esempio pratico di applicazione del paradigma RAG consiste nello sviluppo di un chatbot aziendale in grado di rispondere a domande sfruttando una knowledge base interna composta da file, documenti e wiki aziendali.
Stack Tecnologico
- Copilot Studio per la progettazione, l’orchestrazione, la pubblicazione e il monitoraggio di chatbot e agenti conversazionali avanzati
- Azure AI Foundry per la gestione e l’orchestrazione di workflow di intelligenza artificiale, sfruttando le potenzialità di Azure Machine Learning per strutturare pipeline, automatizzare processi, e coordinare i vari componenti
- Prompt Flow facilita la creazione, il testing e la messa in produzione di workflow basati su prompt, orchestrando chiamate tra diversi servizi come retrieval, OpenAI, e passaggi di trasformazione
- Azure OpenAI offre l’accesso a Large Language Models (LLM) di ultima generazione, come GPT, tramite API sicure e gestite nel cloud
- Azure AI Search abilita capacità avanzate di indicizzazione, ricerca semantica e recupero delle informazioni da fonti sia strutturate che non strutturate
- Azure Blob Storage per l’archiviazione scalabile di oggetti, fungendo da repository centrale, che alimentano i servizi AI
Architettura e Flusso
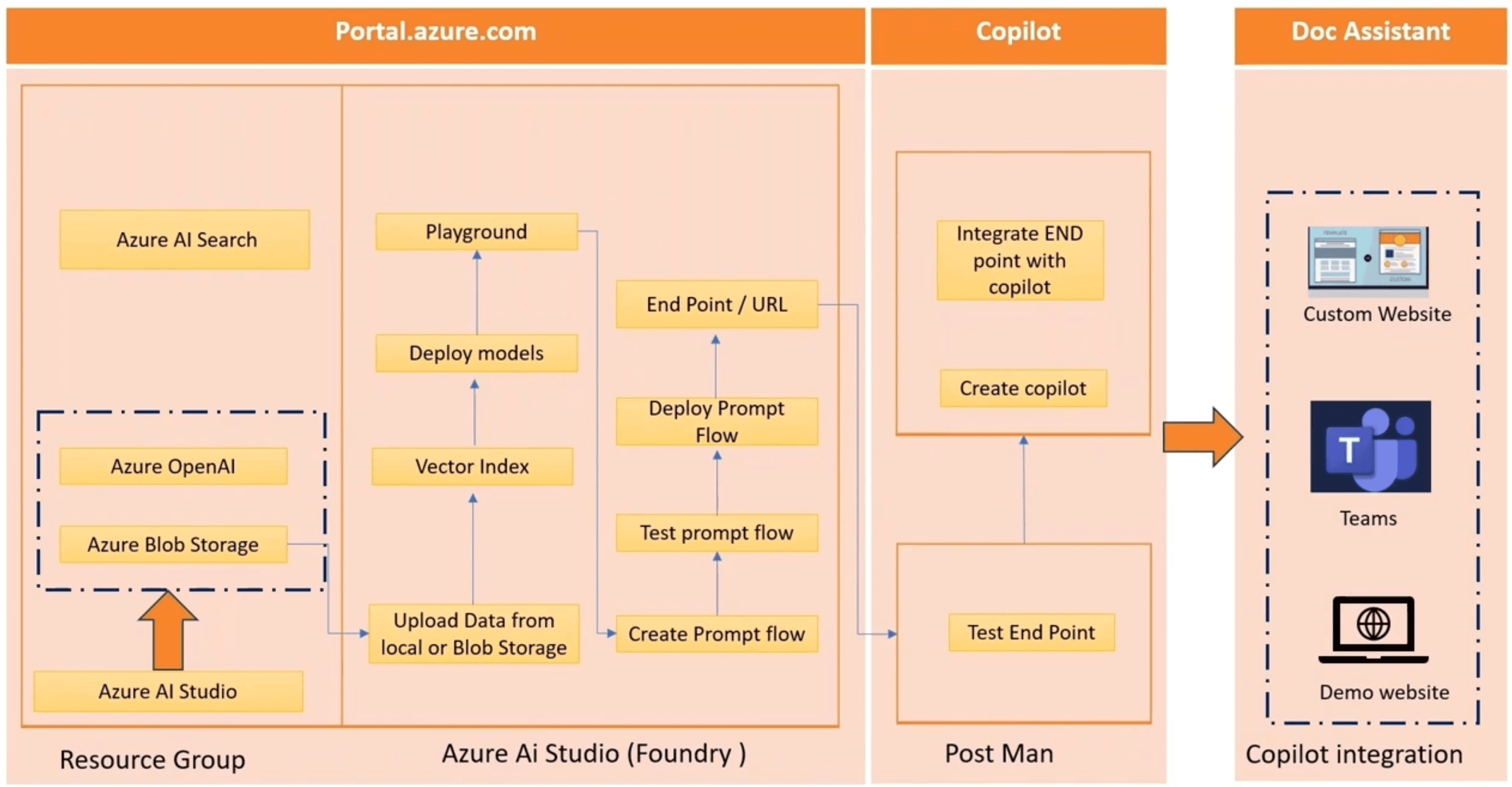
- Repository aziendale: tutte le fonti informative vengono raccolte e centralizzate, spesso su un sistema scalabile come Azure Blob Storage
- Indicizzazione e vettorializzazione con Azure AI Search: i contenuti provenienti dal repository vengono processati e indicizzati dal servizio, che trasforma i dati in vettori grazie all’integrazione con il modello di embedding
- Definizione dell'agente conversazionale: l'agente viene progettato impostando un flusso che gestisce la ricezione della richiesta, il passaggio della query all’endpoint di retrieval e la restituzione della risposta
- Distribuzione del Prompt Flow: per rendere l’interazione realmente efficace e naturale, viene progettata una pipeline di Prompt Flow multi-turno, che consente al chatbot di conservare il contesto delle domande e delle risposte e di sostenere dialoghi articolati e coerenti nel tempo
Preparazione
La prima fase consiste nella predisposizione dell’ambiente su Azure. Si parte dalla creazione di un resource group, che funge da contenitore logico per tutte le risorse del progetto.
È sufficiente cercare "Azure AI Foundry" utilizzando la barra di ricerca del portale Azure per accedere a un’interfaccia centralizzata attraverso la quale è possibile creare, configurare e monitorare tutte le risorse Azure AI richieste dal progetto—come Azure AI Search e l'hub di Azure AI Foundry—senza dover navigare singolarmente tra i vari servizi.
Dopo aver creato il servizio Azure AI Search e Azure Storage Account, il passo successivo prevede il caricamento dei file aziendali che costituiranno la knowledge base a cui fare riferimento. Questi documenti vengono inseriti all’interno di un container specifico dello storage blob.
E' necessario procedere con la creazione dell’hub all’interno di Azure AI Foundry.

L’avvio della creazione tramite l’apposito wizard guida l’utente attraverso i passaggi fondamentali: si collega lo storage account precedentemente configurato, si configura un Azure Key Vault per la gestione sicura delle credenziali e dei segreti, e si imposta il servizio Azure AI services base models (Connect AI Services), che può includere l’integrazione con modelli OpenAI.
Azure AI Foundry
Successivamente si procede con la configurazione in Azure AI Foundry accedendo allo studio.
Aprendo lo Studio, si entra in un ambiente dedicato dove è possibile orchestrare tutte le attività operative associate al progetto selezionato.
Da questa interfaccia, il passo successivo consiste nella distribuzione (deployment) dei modelli AI necessari: in questo caso del modello generativo GPT-4.1 e del modello embedding-large-text-3 per la rappresentazione vettoriale dei dati testuali.
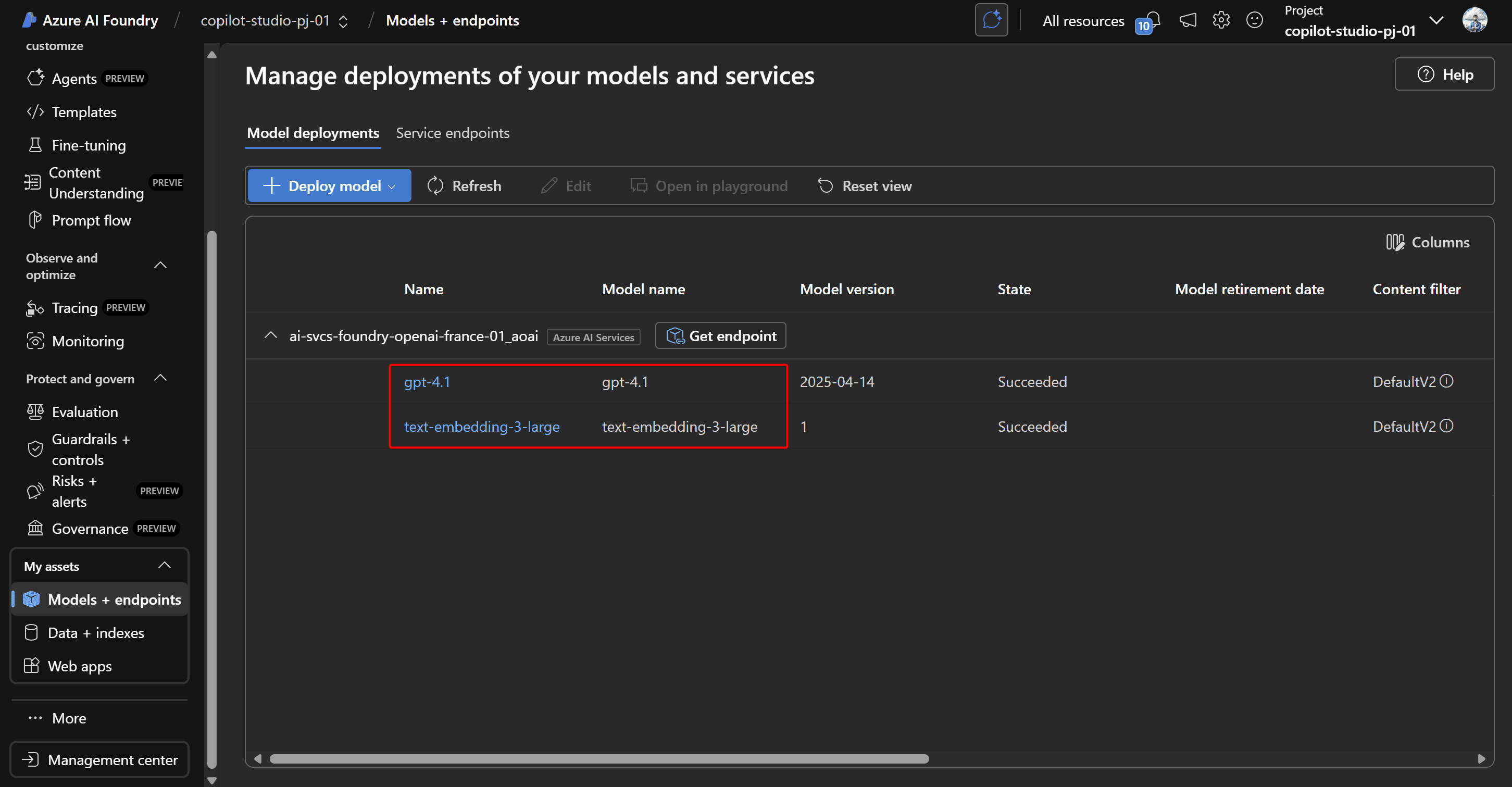
All’interno della sezione "Data + Indexes" è possibile configurare la connessione al container precedentemente creato e indicare quali file dovranno essere utilizzati come sorgente.
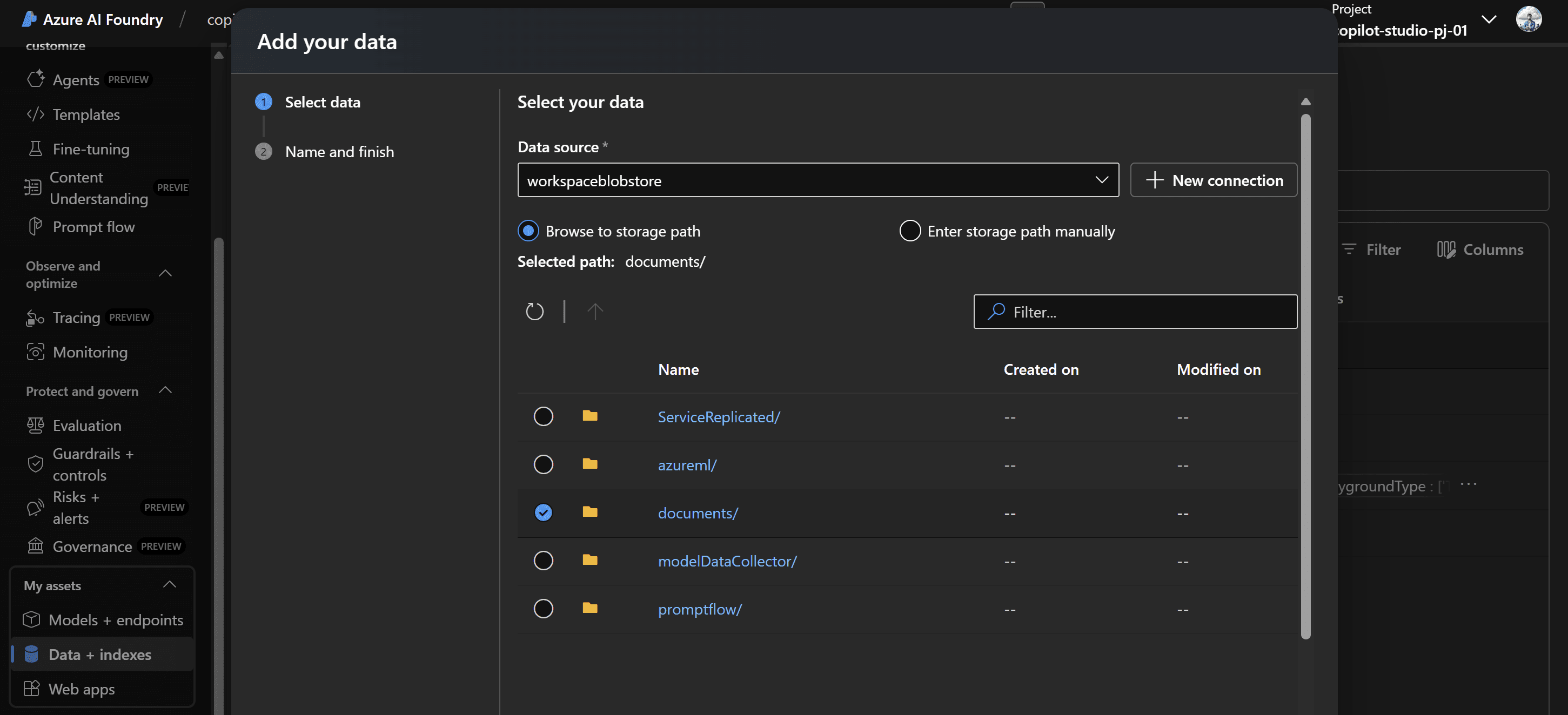
Lo step successivo prevede la creazione dell’indice. Si seleziona innanzitutto il data source, ovvero il percorso del container nello storage account che contiene i file da indicizzare.
Durante la configurazione dell’indice, viene specificato quale servizio Azure AI Search utilizzare e si assegnano le risorse computazionali che saranno impiegate per il processo di indexing, il quale verrà eseguito tramite una pipeline orchestrata con Azure Machine Learning.
In questa fase, si configurano anche le impostazioni avanzate di ricerca: combinando il retrieval ibrido, che sfrutta sia la ricerca full-text sia la semantica, con il semantic ranking si garantisce la massima accuratezza nella restituzione dei risultati.
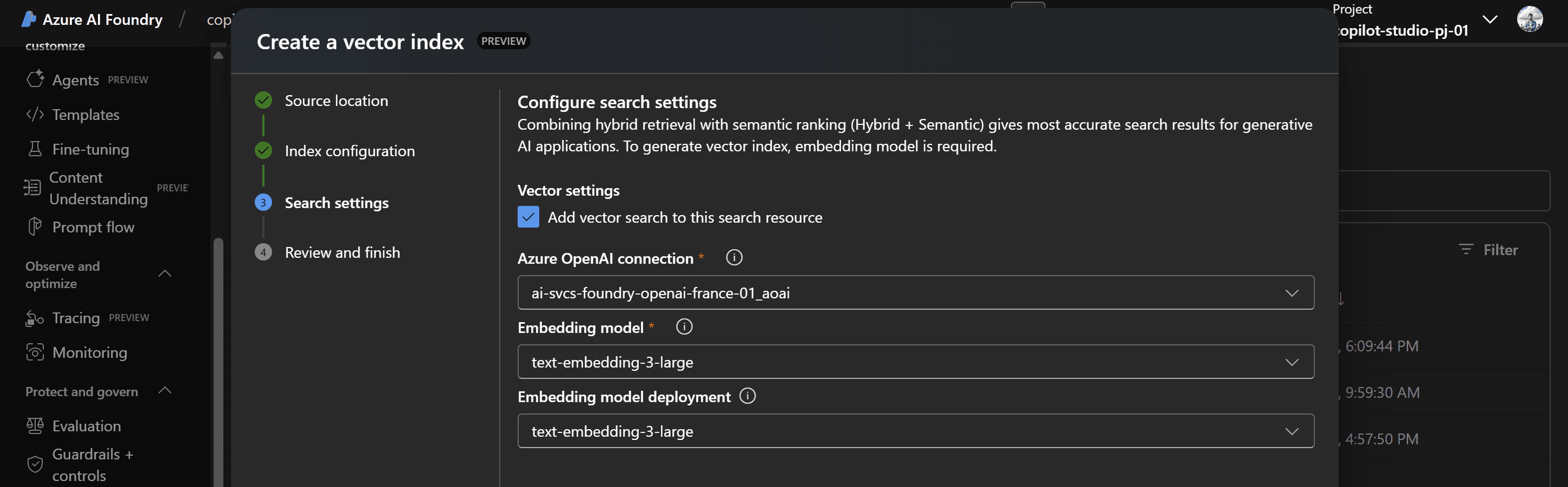
La generazione degli indici vettoriali richiede l’utilizzo di un modello di embedding: per abilitare questa funzionalità, si indica la connessione ad Azure OpenAI e si seleziona il modello di embedding precedentemente distribuito.
Tutte le operazioni vengono orchestrate come un job all’interno di Azure Machine Learning Studio. Accedendo alla sezione “Jobs” dello studio, è possibile monitorare in tempo reale lo stato di avanzamento: dalla fase iniziale di acquisizione e suddivisione dei documenti, alla generazione degli embeddings, fino all’aggiornamento e alla registrazione dell’indice vettoriale.
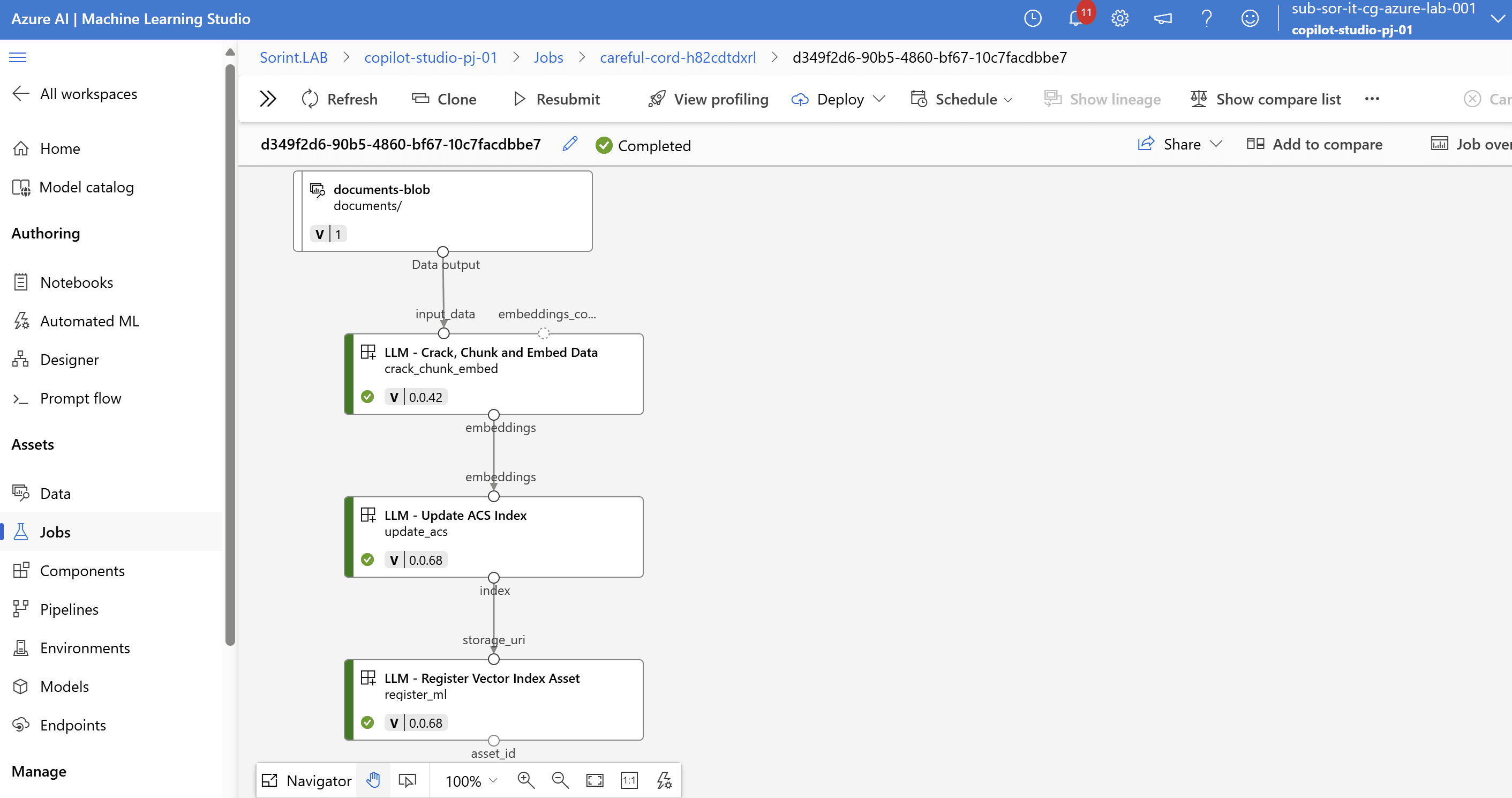
L’interfaccia grafica mostra la pipeline con le varie fasi e i relativi output, permettendo di verificare rapidamente l’esito di ogni step, consultare i dettagli e gestire eventuali errori.
Si passa poi alla creazione del Prompt Flow.
Per semplificare questa attività, si può partire da un template già pronto per il multi-round Q&A, progettato appositamente per gestire conversazioni a più turni e mantenere il contesto. Clonando il template, si accede a una configurazione guidata che permette di personalizzare ogni step del workflow.
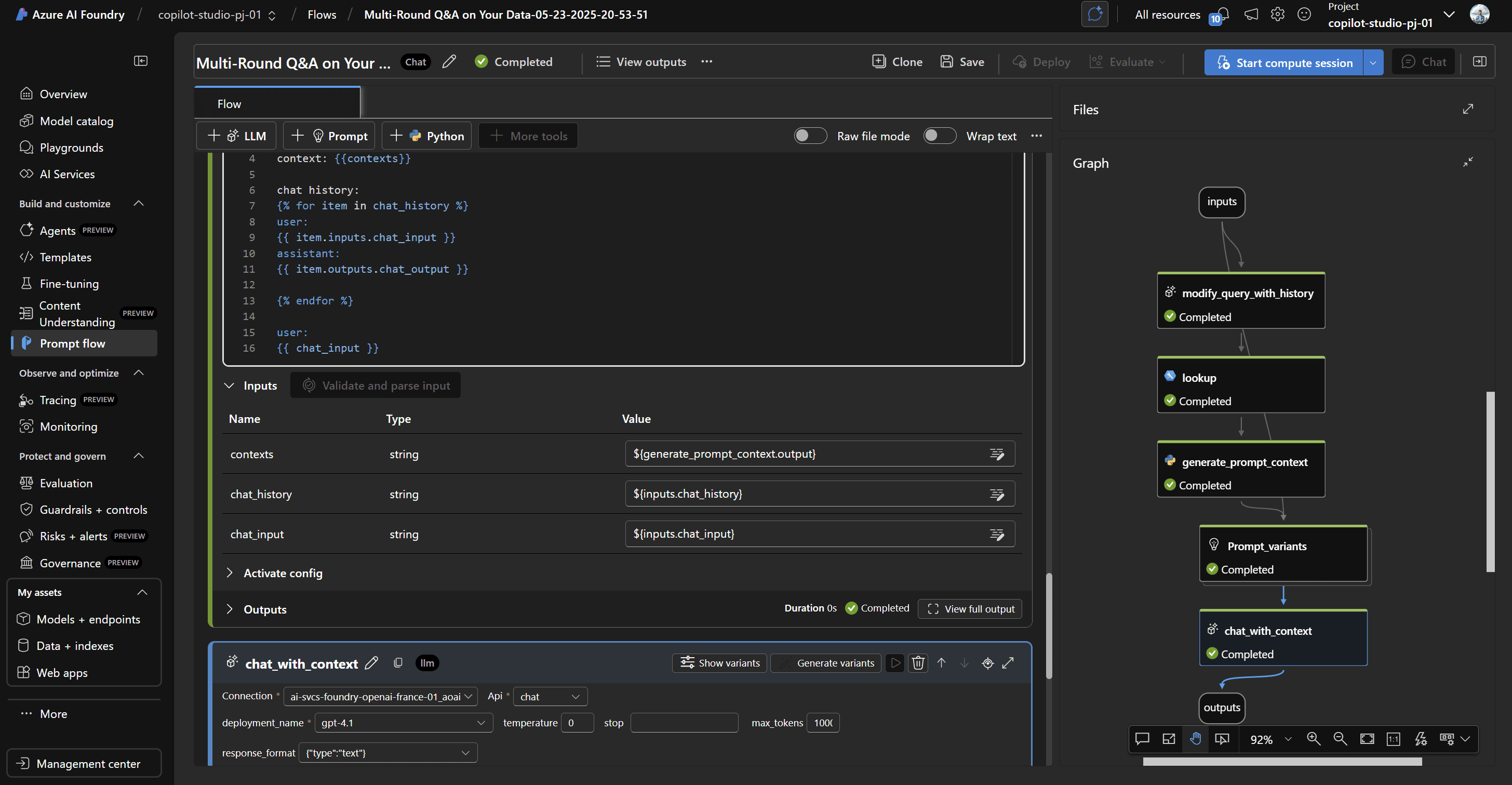
E' necessario impostare i riferimenti al servizio OpenAI specificando il deployment del modello GPT-4.1 per la generazione delle risposte, selezionare il modello di embedding, definire il formato dell’output (ad esempio impostando response format type = text) e scegliere la tipologia di query (query type = hybrid) per sfruttare sia il retrieval semantico che quello tradizionale.
Terminata la personalizzazione è possibile effettuare un test utilizzando il playground. Confermato il corretto funzionamento, si procede con il deploy del Prompt Flow.
È importante, prima di avviare la pubblicazione, assicurarsi che sia stata attivata una compute session: ciò permette di destinare le risorse necessarie per eseguire il flusso.
Il deploy viene effettuato su un managed online endpoint, che abilita l’inferenza real-time tramite REST API.
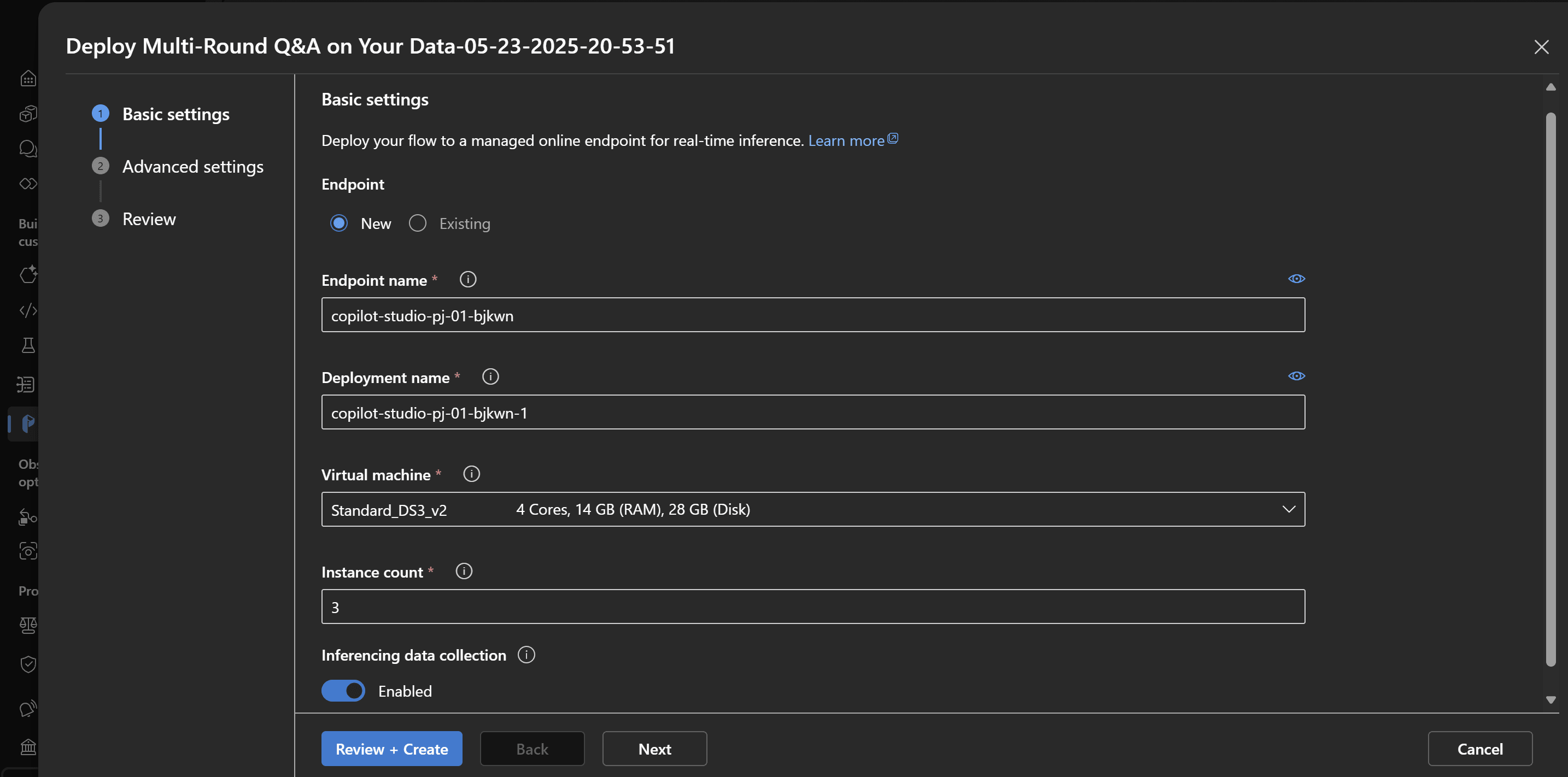
Durante questa fase, si dovrà scegliere il numero di istanze compute da dedicare al servizio (solitamente vengono consigliate almeno 3 istanze per assicurare alta affidabilità e disponibilità) e definire la dimensione delle risorse in base ai volumi e alle esigenze dell’applicazione.
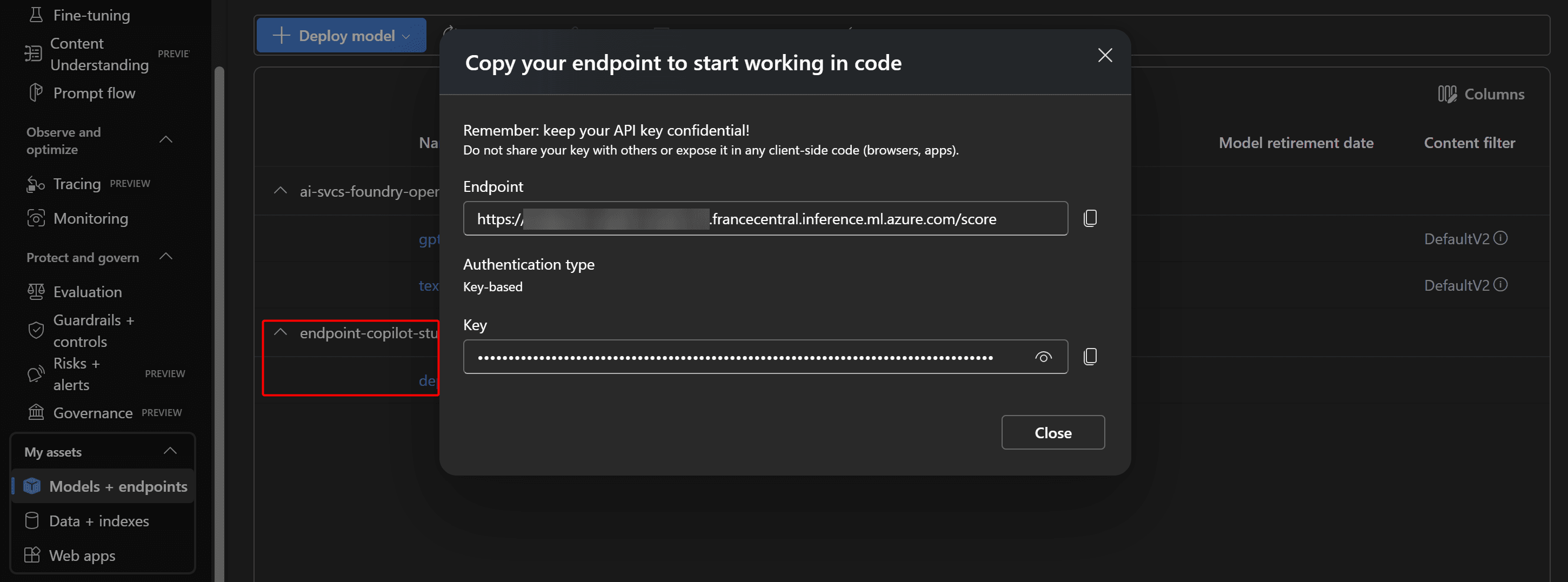
Al termine del deploy del Prompt Flow, viene generato un endpoint online con la relativa URL e chiave di accesso (API key). Queste informazioni vanno annotate, poiché serviranno in Copilot Studio per configurare l’azione di chiamata ed integrare la logica all’interno dell'agente.
Per impostazione predefinita, l’endpoint viene eseguito in modalità serverless, consentendo una gestione automatica delle risorse senza configurazione manuale. Il monitoraggio dell’attività e delle risorse allocate è sempre accessibile dalla sezione Compute di Azure Machine Learning Studio.
In alternativa, per esigenze specifiche di scalabilità o controllo dei costi, è possibile distribuire anche su macchine dedicate o cluster Kubernetes, garantendo così maggiore personalizzazione e ottimizzazione in ambienti produttivi più complessi.
Copilot Studio
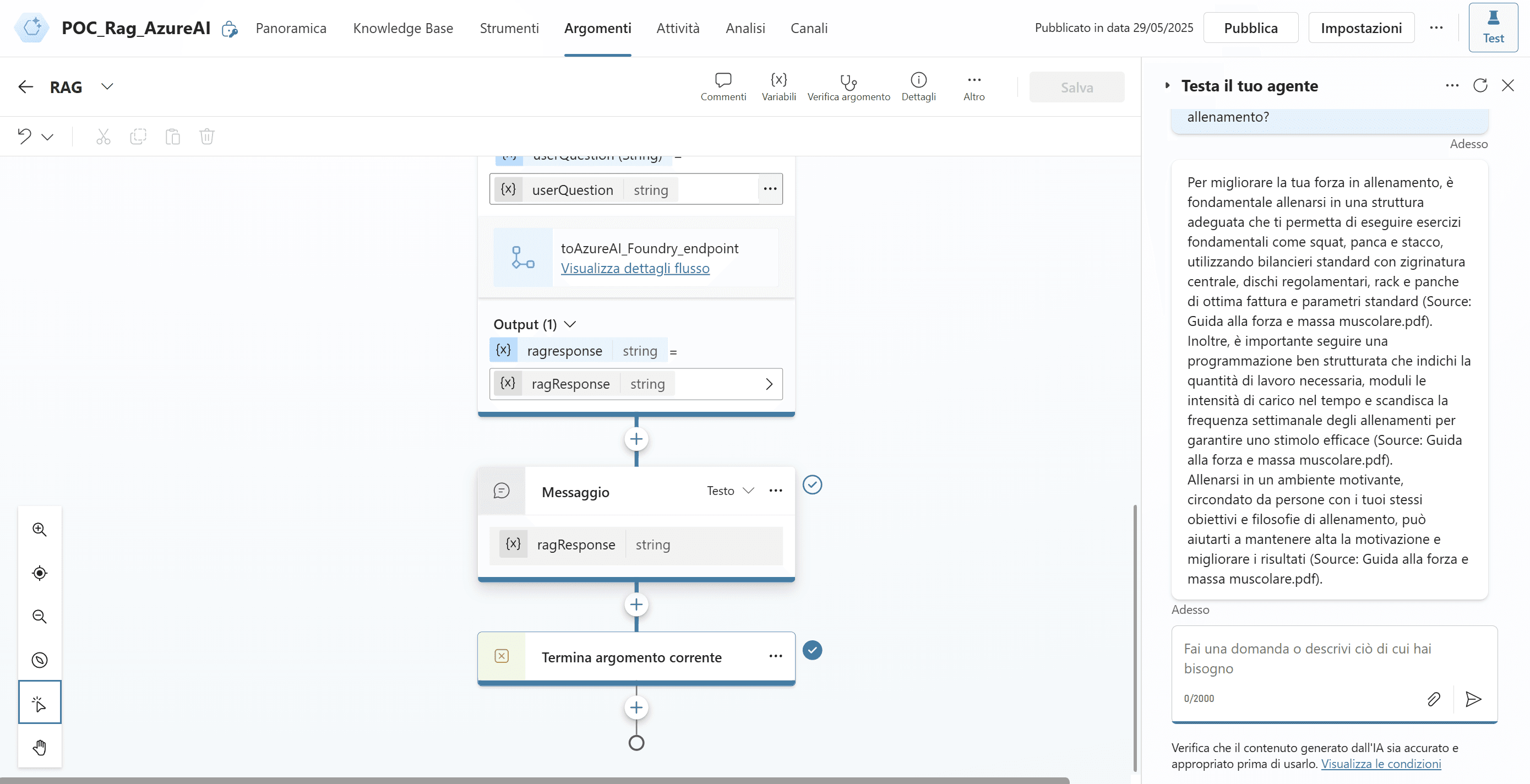
Proseguendo in Copilot Studio, si crea il nuovo agente conversazionale dedicato al progetto.
Dopo la creazione dell’agente, è importante disabilitare tutti gli argomenti preimpostati e la knowledge base generale eventualmente attiva. Questa operazione previene che il bot dia risposte attingendo da fonti o logiche generiche, così da garantire che tutte le interazioni siano gestite unicamente dal flusso RAG.
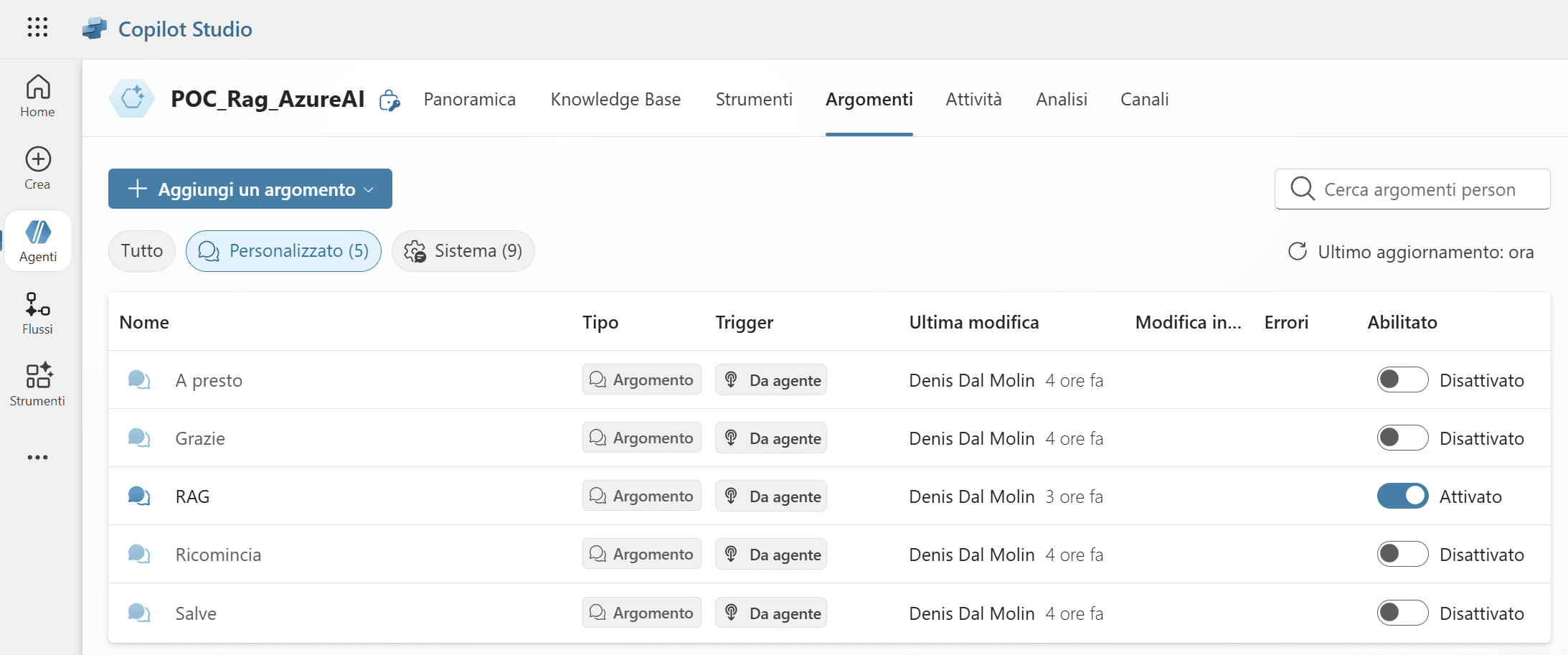
A questo punto si procede alla creazione di un nuovo topic specifico per la gestione delle richieste RAG.
All’interno di questo topic si configurano le azioni necessarie: dalla ricezione della domanda dell’utente, all’invocazione tramite chiamata HTTP POST verso l’endpoint in Azure AI Foundry, fino alla restituzione della risposta generata.
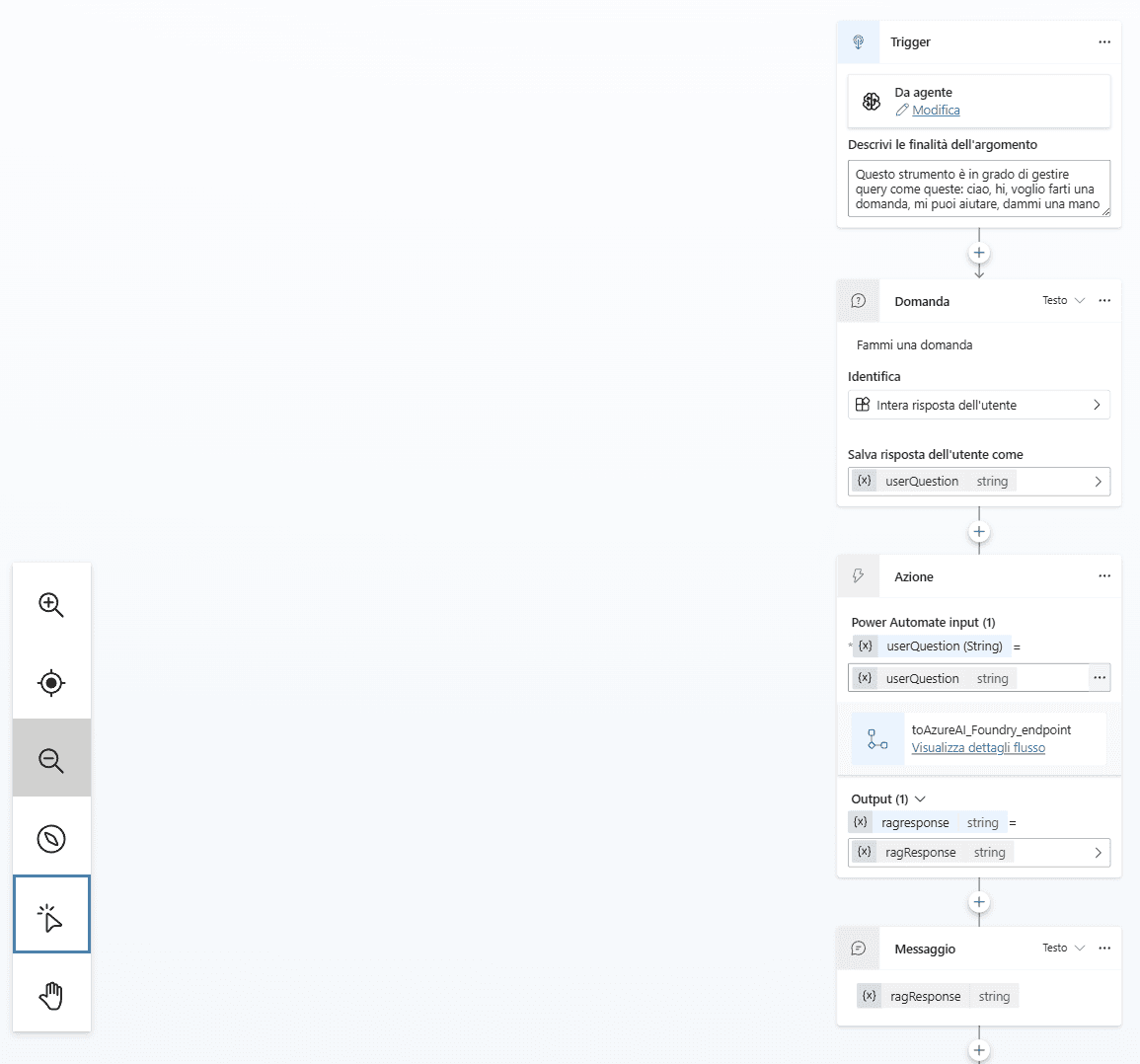
L’azione di chiamata all’endpoint viene aggiunta come nodo nel flusso dell’agente. Questa azione viene gestita direttamente dalla finestra di design dei virtual agent.
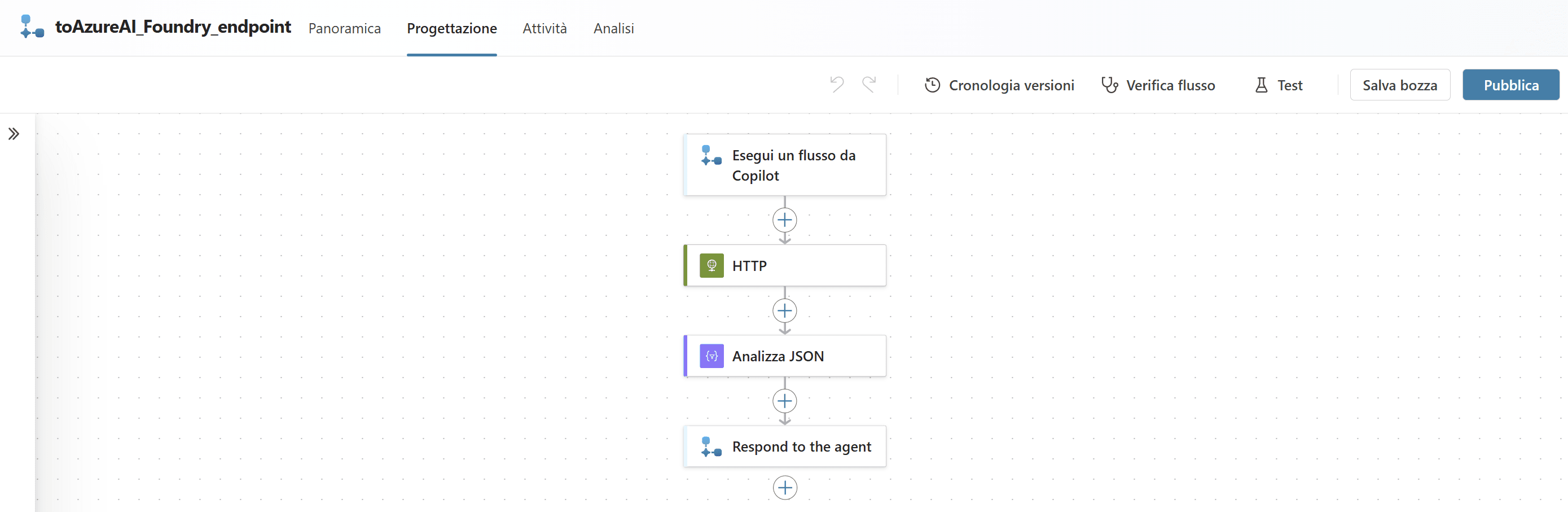
A questo punto, è possibile testare il funzionamento dell’agente utilizzando l’ambiente di chat integrato.