IA - L'autostrada dell'informazione
-
Denis Dal Molin
- 08 Jan, 2026
- 04 Mins read

Quando parliamo di modelli di intelligenza artificiale sempre più grandi, tendiamo a concentrarci su numeri "facili" da raccontare: parametri, token, FLOPS, dimensioni del dataset.
Ma la domanda che ha bloccato, e poi sbloccato, la scalabilità tecnologica è stata: come facciamo a far viaggiare l’informazione attraverso reti sempre più profonde senza perderla o distruggerla lungo il percorso?
Per capirlo, è utile immaginare una rete neurale come un sistema autostradale. Se le strade sono progettate bene, il traffico può crescere senza collassare. Se sono progettate male, basta aumentare il flusso per creare ingorghi, incidenti o blocchi totali.
Quando "più profondo" significa "peggiore"
L’intuizione iniziale: se una rete neurale funziona, aggiungiamo più strati e funzionerà meglio.
In pratica però succedeva spesso l’opposto.
Reti più profonde:
- non miglioravano le performance
- convergevano più lentamente
- oppure smettevano proprio di imparare
Il problema non era la mancanza di dati o di potenza computazionale. ma il segnale.
Durante l’addestramento, l’informazione percorre due direzioni:
- in avanti, quando l’input attraversa gli strati fino a produrre un output
- all’indietro, quando il gradiente della perdita viene propagato per aggiornare i parametri del modello
Con reti poco profonde questo meccanismo funziona, ma aumentando gli strati il gradiente tende a diventare sempre più piccolo (vanishing gradient) fino a scomparire del tutto.
Loss e Gradiente
Prima di entrare nel dettaglio vale la pena fermarsi un attimo su due concetti fondamentali che spesso vengono dati per scontati. Ogni modello di Intelligenza Artificiale, per quanto sofisticato, impara sempre nello stesso modo: commettendo errori e cercando di ridurli.
La loss function è la misura numerica di questo errore, una funzione che confronta:
- ciò che il modello ha prodotto in output
- con ciò che avrebbe dovuto produrre
Più la loss è alta più il modello sta sbagliando, più è bassa più il modello si sta avvicinando al comportamento desiderato. Ma sapere quanto stiamo sbagliando non basta. Serve capire come correggersi e qui entra in gioco il gradiente.
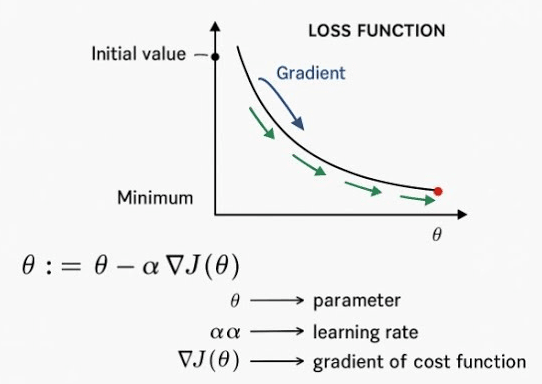
Il gradiente è, in sostanza, il segnale di correzione e indica:
- in quale direzione modificare i parametri del modello
- e di quanto farlo per ridurre la loss
Durante l’addestramento:
- l’input attraversa la rete in avanti (feed-forward) fino a produrre un output
- viene calcolata la loss
- il gradiente di quella loss viene propagato all’indietro, layer dopo layer, aggiornando i pesi
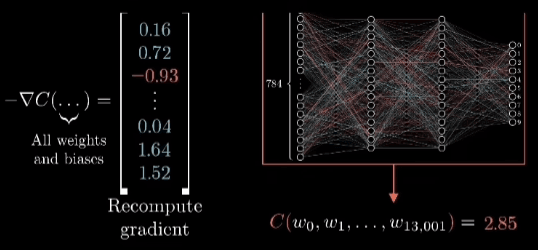
Questo processo si chiama backpropagation.
ResNet
Il vero punto di svolta arriva nel 2016 con l’introduzione delle Residual Networks (ResNet).
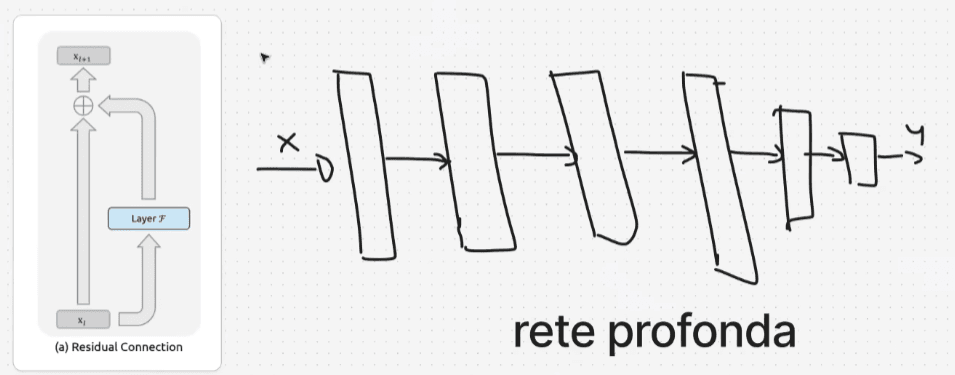
L’idea è molto semplice: invece di forzare ogni strato a trasformare completamente l’input, permettiamogli di saltare alcuni blocchi e propagarsi direttamente in avanti.
Formalmente l’input xxx non viene solo trasformato da una funzione F(x)F(x)F(x) ma viene anche aggiunto direttamente all’output. Questo crea una mappatura identitaria: un percorso garantito attraverso cui l’informazione può fluire senza essere distorta.
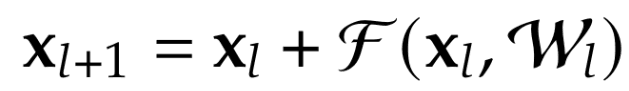
Dal punto di vista dell’autostrada non è più una sequenza di strade secondarie ma una corsia preferenziale sempre aperta.
Il risultato è:
- i gradienti riescono a propagarsi anche in reti molto profonde
- l’addestramento diventa stabile
- “più profondo” torna ad avere senso
Il limite delle connessioni residue
Le residual connections funzionano, ma hanno un limite strutturale: sono un singolo percorso.
Quando i modelli iniziano a crescere, una sola corsia non è più sufficiente per gestire:
- la complessità delle rappresentazioni
- la quantità di informazione che deve fluire
- la necessità di maggiore espressività
Da qui nasce, più recentemente, il concetto di hyper-connections (HC). Invece di un unico flusso di dimensione CCC, l’informazione viene suddivisa in più flussi paralleli (tipicamente n=4n = 4n=4).

L’autostrada diventa più larga, con più corsie che viaggiano in parallelo.
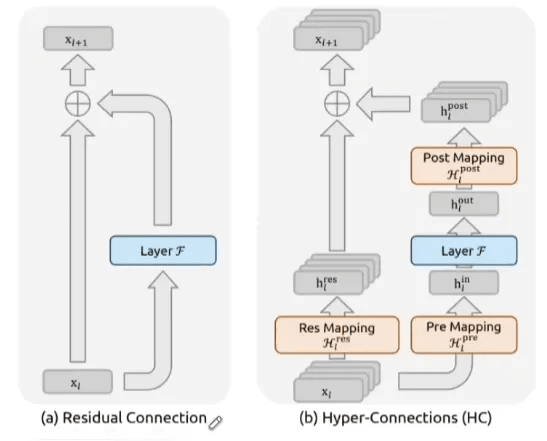
Ma si introduce un altro problema, moltiplicare i percorsi senza regole chiare porta a un effetto collaterale di instabilità.
Con più flussi che interagiscono:
- piccoli cambiamenti in un layer iniziano a sommarsi
- i gradienti possono crescere invece di attenuarsi
- il modello “disimpara” invece di imparare
È il fenomeno opposto al vanishing gradient: gradient explosion.
In termini di autostrade:
- non ci sono più corsie ben delimitate
- il traffico si incrocia senza regole
- gli incidenti diventano inevitabili
Non è l’idea delle hyper-connections in sé, ma l’assenza di vincoli strutturali.
Autostrade vincolate matematicamente (mHC)
La soluzione più recente è elegante perché non aggiunge complessità inutile: aggiunge regole.
Nel 2025 vengono introdotte hyper-connections vincolate da una struttura matematica precisa: le matrici doppiamente stocastiche, mappate su un politopo di Birkhoff.
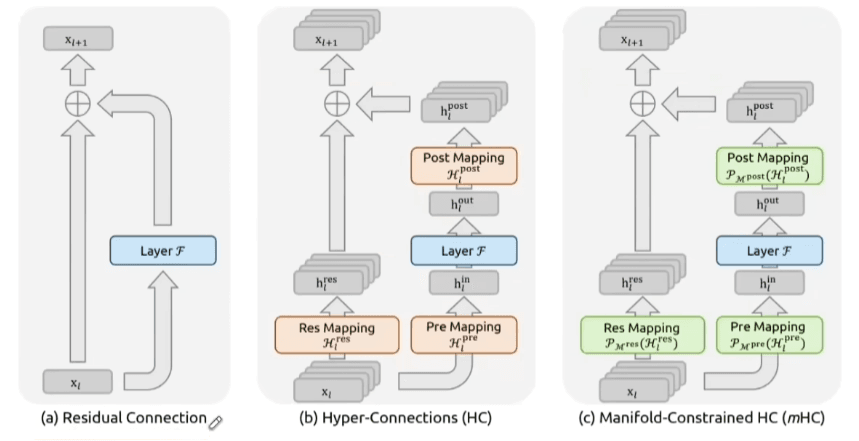
La mappatura residua viene vincolata in modo che:
- tutte le voci siano non negative (nessuna cancellazione del segnale)
- ogni riga sommi a 1 (la potenza del segnale in avanti è conservata)
- ogni colonna sommi a 1 (anche il gradiente all’indietro è conservato)
Il risultato:
- la stabilità è garantita a qualsiasi profondità
- moltiplicare queste matrici produce ancora matrici stabili
- il flusso informativo resta sotto controllo
Per ottenere tutto questo nella pratica, si utilizza l’algoritmo Sinkhorn-Knopp (1967), che normalizza iterativamente righe e colonne fino alla convergenza.
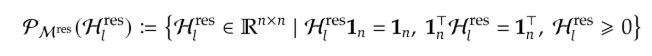
Dopo una ventina di iterazioni, otteniamo un’autostrada a molte corsie dove:
- il traffico è regolato
- non ci sono ingorghi
- l’informazione fluisce senza degradarsi
La parte più interessante è che le performance migliorano anche a parità di tutto il resto:
- stessi dati
- stesso numero di parametri
- stessa architettura di alto livello
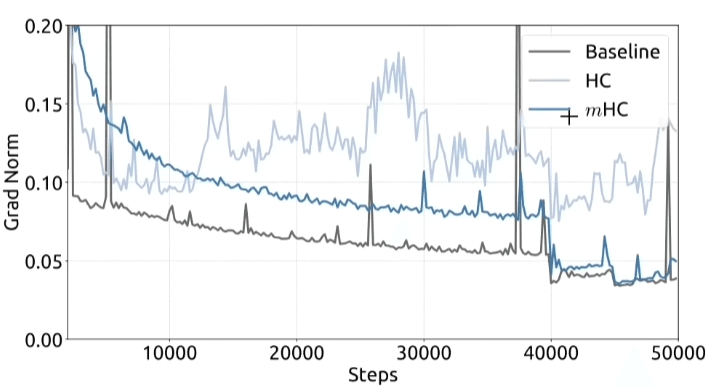

Ovviamente ci sono dei costi:
- maggiore utilizzo di memoria (VRAM)
- maggiore spesa computazionale
Ma con ottimizzazioni di basso livello – come la riscrittura dei kernel GPU e l’adozione di strategie di scheduling come il dual-pipe – l’overhead può essere contenuto (circa +6% di computazione).
E soprattutto: il vantaggio cresce con la scala. Più il modello è grande, più questi accorgimenti diventano determinanti.
Una lezione più ampia sulla scalabilità
Questa evoluzione ci lascia una lezione che va oltre il singolo paper o la singola architettura:
Scalare l’Intelligenza Artificiale non significa solo aggiungere parametri, ma progettare sistemi in cui l’informazione possa muoversi in modo stabile, controllato e prevedibile.
È una lezione valida tanto per chi costruisce modelli fondamentali, quanto per chi lavora su piattaforme cloud, infrastrutture distribuite o sistemi complessi in generale.
Prima di chiederci quanto grande può diventare un modello, dovremmo sempre chiederci:
quanto bene è progettata la sua autostrada interna dell’informazione.
Ed è spesso lì che si gioca la vera partita.